


Data engineering is a fast-growing and in-demand field, especially with the rise of AI and machine learning. Companies need skilled people to handle and organize large amounts of data, making it a great career choice for those looking for stable and rewarding work. This beginner-friendly guide is perfect for students or professionals considering switching careers.
It provides a clear, step-by-step plan for learning data engineering, covering important skills, useful tips, and a timeline for getting job-ready. By the end, you'll understand what a data engineer does, how to begin your learning journey, and find answers to common questions to help you start strong in this exciting field.
Why Learn Data Engineering?
Data powers everything from small startups to global tech giants, and data engineers are the ones who make that data usable. With excellent salaries, growing demand, and opportunities across industries like tech, finance, and healthcare, data engineering is a future-proof career choice. Whether you're a tech expert or a beginner, this field offers great opportunities for those who enjoy solving problems and want to keep learning and growing.
What Does a Data Engineer Do?
Data engineers are the architects of data systems, ensuring data is collected, processed, and stored efficiently for teams to use. Their work supports analytics, AI, and business decisions by keeping data reliable and accessible. Here’s a detailed look at their core responsibilities:
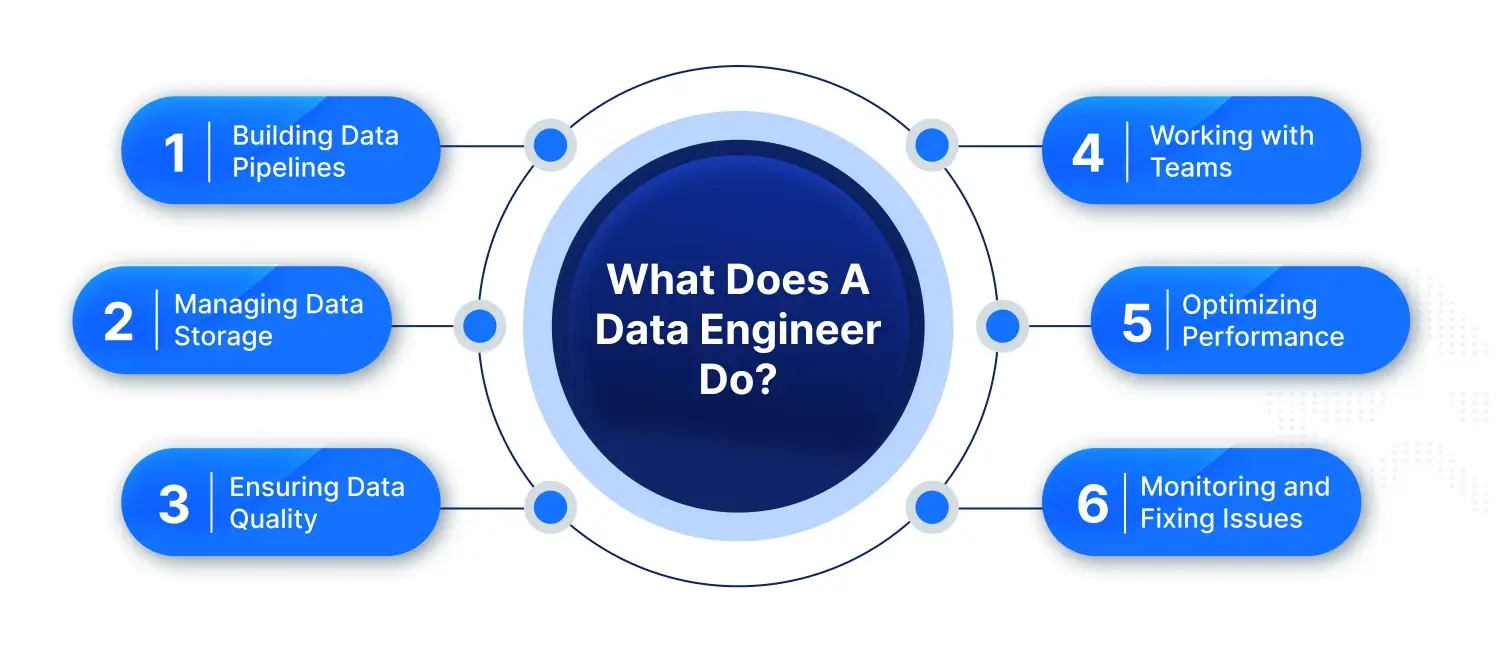
- Building Data Pipelines: Data engineers design workflows to transport data from various sources, such as apps or databases, to centralized storage systems like data warehouses. This process, called ETL (Extract, Transform, Load), ensures data is ready for analysis. It involves:
- Extracting raw data from sources like APIs, databases, or logs.
- Cleaning and transforming it into a consistent, usable format.
- Loading it into storage systems for easy access by other teams.
- Managing Data Storage: Data engineers select and maintain storage solutions tailored to the data’s type and volume, ensuring security and efficiency. They work with relational databases for structured data, NoSQL for flexible data, or cloud storage for scalability. This includes:
- Using relational databases like MySQL for organized data, such as customer records.
- Implementing NoSQL databases like MongoDB for unstructured data, like social media posts.
- Leveraging cloud platforms like Amazon S3 for cost-effective, scalable storage.
- Ensuring Data Quality: High-quality data is critical for trustworthy analysis, so data engineers implement checks to maintain accuracy and consistency. They prevent errors, duplicates, or incomplete data that could lead to flawed decisions. This involves:
- Setting up validation rules to catch errors automatically.
- Removing duplicate or inconsistent records.
- Monitoring data integrity throughout its lifecycle.
- Working with Teams: Data engineers collaborate closely with data scientists, analysts, and software engineers to meet their data needs. By understanding team goals, they ensure data systems align with the company’s objectives. This includes:
- Providing clean datasets for data scientists to build machine learning models.
- Supporting analysts with reliable data for reports and dashboards.
- Integrating data pipelines with applications built by software engineers.
- Optimizing Performance: As data volumes grow, data engineers ensure systems remain fast and scalable to handle large datasets without delays. This is especially crucial for companies processing massive data, like streaming platforms or e-commerce giants. They focus on:
- Tuning pipelines to process data efficiently.
- Reducing latency in data workflows.
- Scaling systems to manage increasing data demands.
- Monitoring and Fixing Issues: Data systems can encounter failures, so data engineers set up tools to detect and resolve issues quickly. They ensure pipelines run smoothly to avoid disruptions in data flow. This involves:
- Creating alerts for pipeline errors or performance slowdowns.
- Troubleshooting issues like data inconsistencies or system crashes.
- Maintaining reliable systems critical to business operations.
Data Engineering vs Other Roles
Data engineering stands apart from related fields, though it shares some overlap. Understanding these distinctions helps clarify if this career suits you:
- Data Engineering: Focuses on creating and managing systems to collect, process, and store data for other teams to use. Data engineers build the infrastructure behind data-driven decisions. Example: A pipeline that aggregates website traffic data into a data warehouse.
- Data Science: It involves analyzing data to uncover insights or develop predictive models, relying on data prepared by engineers. Data scientists focus on patterns and predictions. Example: Building a model to predict customer purchases based on historical data.
- Data Analysis: Centers on interpreting data to create reports or visualizations for business decisions. Analysts turn data into actionable insights. Example: A dashboard showing monthly sales performance.
- DevOps: Concentrates on deploying and maintaining applications, while data engineers specialize in data-specific systems. DevOps ensures overall system reliability. Example: Automating app deployment, not data pipelines.
Skills You Need to Become a Data Engineer
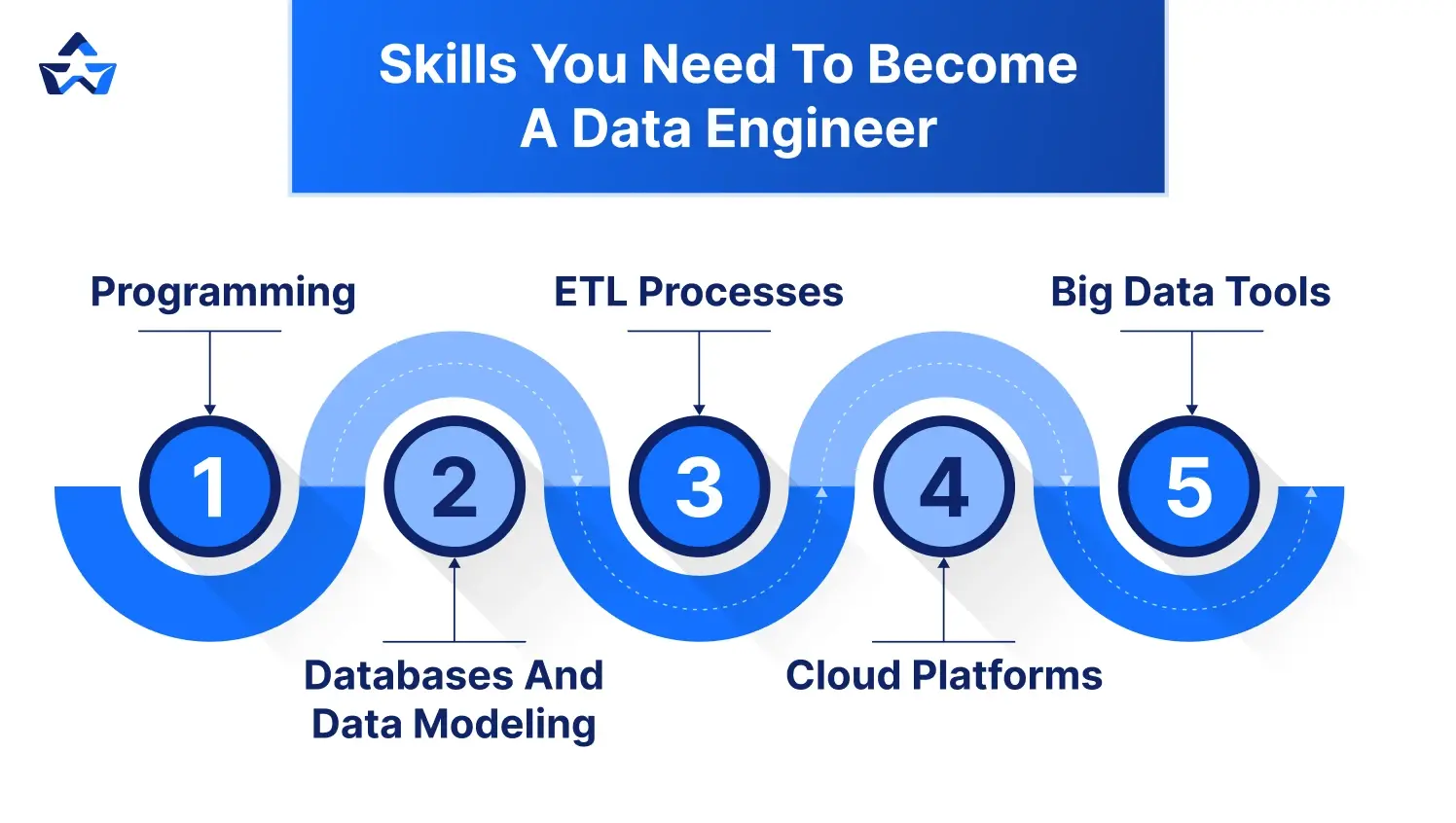
Data engineering requires a blend of technical expertise and soft skills to build robust systems and work effectively in teams. These skills are learnable, even for beginners.
Technical Skills
- Programming: Programming is the cornerstone of data engineering, enabling automation and data manipulation. Python and SQL are essential, with Java or Scala as optional add-ons for advanced tools. Key areas include:
- Python: Used for scripting, data processing, and building pipelines with libraries like Pandas.
- SQL: Essential for querying and managing data in databases.
- Java/Scala: Relevant for big data frameworks like Apache Spark.
- Databases and Data Modeling: Understanding databases ensures data is stored and accessed efficiently. Data engineers design schemas and optimize queries for performance. This includes:
- Relational Databases: Tools like PostgreSQL for structured data.
- NoSQL Databases: Systems like MongoDB for flexible, unstructured data.
- Data Warehouses and Lakes: Snowflake or Amazon S3 for analytics and raw data storage.
- ETL Processes: ETL is the heart of data engineering, moving data through extraction, transformation, and loading stages. Tools like Apache Airflow streamline these workflows. This involves:
- Extracting data from APIs, databases, or logs.
- Transforming it into a clean, usable format.
- Loading it into storage systems for analysis.
- Cloud Platforms: Cloud systems offer scalable, cost-effective solutions for data storage and processing. Familiarity with major platforms is a must. Key platforms include:
- AWS: Services like S3 and Redshift for storage and warehousing.
- Azure: Tools like Data Factory for pipeline management.
- Google Cloud: BigQuery for large-scale analytics.
- Big Data Tools (Optional): For handling massive datasets, big data tools are sometimes needed, especially in large organizations. These tools process data at scale or in real time. This includes:
- Apache Spark: For fast, distributed data processing.
- Kafka: For real-time data streaming, like user activity tracking.
Soft Skills
- Problem-Solving: Data engineers tackle complex issues like pipeline failures or data errors. Strong problem-solving skills help resolve these efficiently. This is key to maintaining reliable systems.
- Collaboration: Working with data scientists, analysts, and engineers requires teamwork. Understanding their needs ensures that data systems support business goals.
- Communication: Explaining technical concepts to non-technical stakeholders is part of the job. Clear communication drives better decisions and project success.
How to Become a Data Engineer: Step-by-Step Roadmap
If your goal is to learn data engineering from scratch and you don’t have a background in tech, this roadmap is made just for you! With steady effort, you can be ready to apply for data engineering jobs in 12 months, or even sooner if you're consistent. In the table below, you’ll find easy-to-follow steps, tools to learn, and example data engineering projects to help you build real skills along the way.
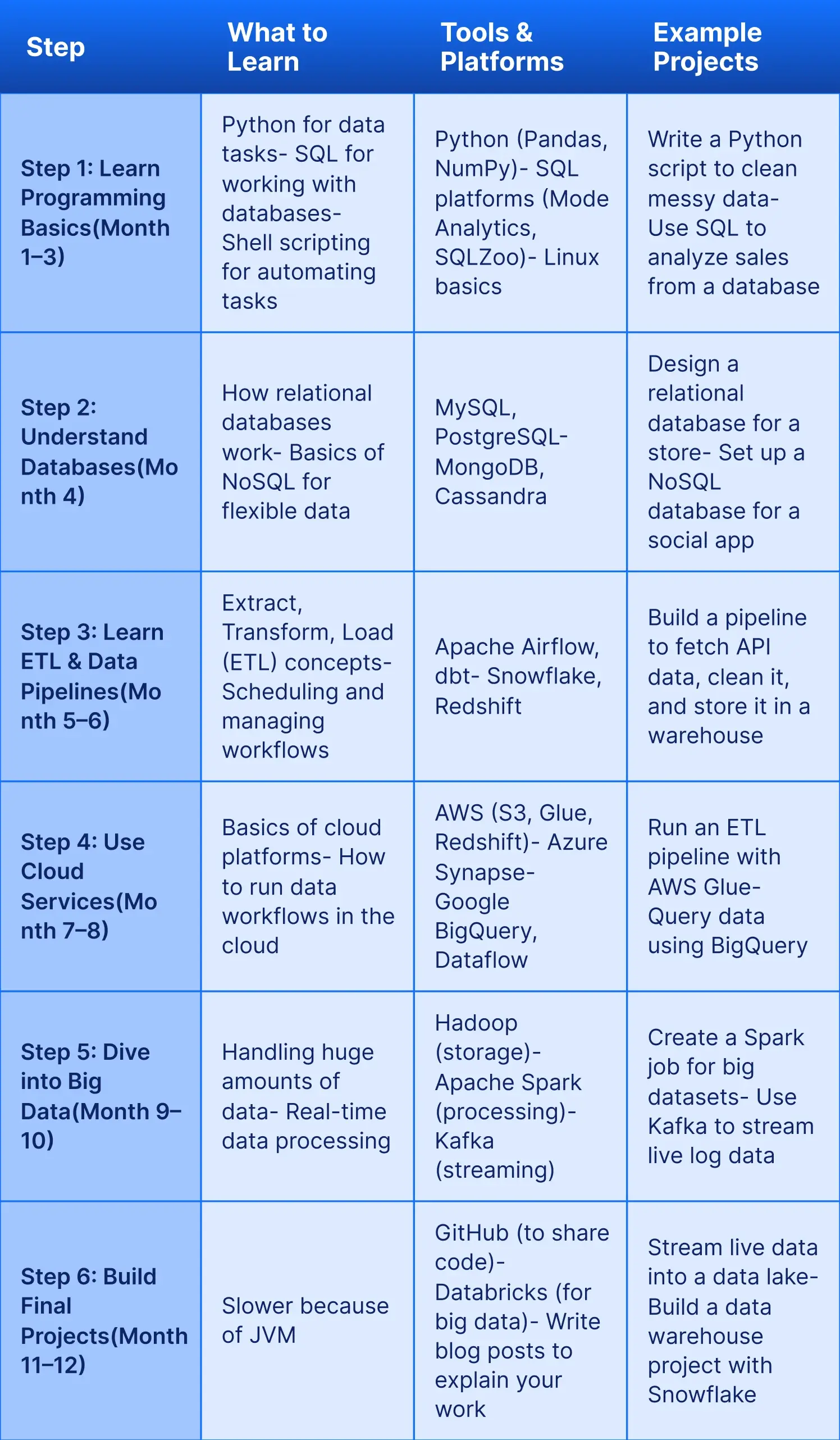
Total Time: 12–18 months (5–10 hours/week). Want more details? Read our full guide, “Complete Data Engineering Roadmap”, for in-depth steps and resources.
Tips to Stand Out
- Focus on Data Quality: Learn validation early to ensure clean data. Good data leads to better results, so always check and fix errors before moving forward.
- Stay Updated: Follow Towards Data Science or r/dataengineering. Reading articles and joining forums helps you learn new tools and trends.
- Network: Join LinkedIn or Reddit communities. Talking to others in the field can lead to advice, support, or even job opportunities.
- Certifications: Consider AWS Certified Data Analytics or Google Cloud’s Professional Data Engineer. These show employers you have real skills and are serious about the field.
Ready to kick-start your data engineering journey? Enroll in Bosscoder Academy’s Data Engineering Course to gain hands-on skills in Python, SQL, ETL, and cloud platforms. With expert guidance and real-world projects, you’ll be job-ready in no time. Sign up today at Bosscoder Academy and take the first step toward a rewarding career!
Conclusion
Learning data engineering from scratch is achievable with a clear plan and consistent effort. By mastering Python, SQL, ETL, and cloud tools, and building projects, you’ll be ready for a thriving career in a field powering AI and analytics. It might feel overwhelming at first, but taking small steps every week adds up over time. Stay curious, keep practicing, and don’t be afraid to make mistakes; they’re part of the learning process. With dedication, you’ll gain the skills and confidence to succeed.
FAQs
Q1. What skills are needed to become a data engineer?
Data engineers need Python, SQL, database knowledge (relational/NoSQL), ETL skills, and cloud platform familiarity (AWS, Azure, Google Cloud). Big data tools like Spark are useful. Soft skills like problem-solving, teamwork, and clear communication are also key. These skills ensure you can build and maintain robust data systems.
Q2. How long does it take to learn data engineering from scratch?
With 5–10 hours weekly, you can be job-ready in 12–18 months, covering programming, databases, ETL, cloud tools, and projects. Prior tech experience can speed this up. Consistent practice is essential to master the concepts.
Q3. What's the difference between a data engineer and a data scientist?
Data engineers build pipelines and manage data systems for reliability. Data scientists analyze this data to find insights or build models, focusing on extracting meaning. Their roles complement each other in data-driven projects.
Q4. Which tools should beginners learn first for data engineering?
Start with Python (Pandas, NumPy), SQL, and Git, then learn PostgreSQL, MongoDB, and Airflow. Next, explore AWS or Google Cloud basics before advanced tools like Spark. These tools form the foundation for real-world data engineering tasks.
Q5. Is data engineering a good career choice in 2026?
Yes, data engineering offers high demand, great salaries, and growth due to AI and data-driven industries. It’s stable, challenging, and versatile across tech, finance, and more. The role’s importance continues to rise with expanding data needs.







