


Big data has become one of the most important technologies in the modern digital world. Companies like Amazon, Netflix, Facebook, and Google generate and process massive amounts of data every day. Traditional systems struggle to store and process such large datasets efficiently.
This is where Apache Hadoop becomes extremely important.
Hadoop is an open-source framework that allows organizations to store and process huge volumes of data across multiple machines. Instead of relying on a single powerful computer, Hadoop distributes the work across many machines, making the system scalable, fault-tolerant, and cost-efficient.
To understand how Hadoop manages massive data efficiently, we need to explore its architecture.
In this blog, we will break down the Hadoop architecture in a simple way, covering its components, working mechanism, and why it is widely used in big data systems.
What is Hadoop Architecture?
Hadoop architecture is the structure or design of the Hadoop ecosystem that enables distributed data storage and processing across clusters of machines.
The architecture mainly consists of:
- HDFS (Hadoop Distributed File System) → for storing large datasets
- YARN (Yet Another Resource Negotiator) → for managing cluster resources
- MapReduce → for processing large data sets
- Hadoop Common → libraries and utilities used by other modules
The most fundamental part of Hadoop architecture is HDFS, which handles data storage and distribution.
Hadoop Distributed File System (HDFS)
HDFS is the storage layer of Hadoop. It stores large files by breaking them into smaller blocks and distributing them across multiple machines in a cluster.
This distributed storage system ensures:
→ High scalability
→ Fault tolerance
→ High data availability
Let’s understand the main components of HDFS.
Key Components of Hadoop Architecture
1. NameNode
The NameNode is the master node in the Hadoop cluster.
It manages the entire file system and keeps track of where the data is stored in the cluster.
Instead of storing the actual data, the NameNode stores metadata, such as:
Example
If a file is stored in Hadoop, the NameNode keeps track of:
File: /home/data/file.txt
Blocks: B1, B2, B3
Replication: 3
Locations: DataNode1, DataNode2, DataNode32. DataNodes
DataNodes are the worker nodes in the Hadoop cluster.
They are responsible for storing the actual data blocks.
Each file in Hadoop is divided into smaller blocks (usually 128MB or 256MB), and these blocks are stored across different DataNodes.
DataNodes perform tasks such as:
→ Storing data blocks
→ Sending heartbeat signals to NameNode
→ Replicating blocks
→ Serving read and write requests
Since Hadoop clusters can have hundreds or thousands of DataNodes, they provide massive storage capacity.
HDFS Architecture Overview
Below is a simplified diagram showing how the NameNode manages metadata while DataNodes store the actual data blocks.
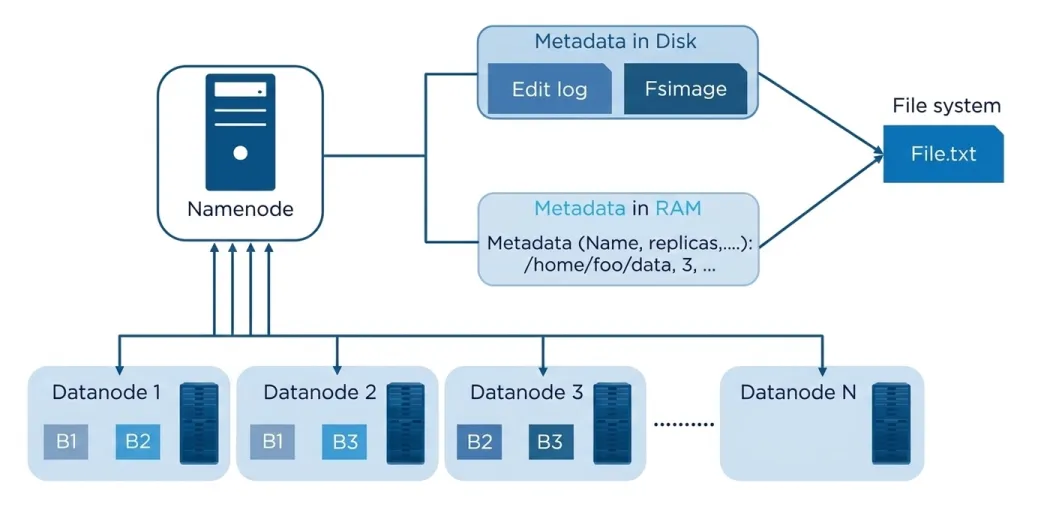
Key idea from the architecture:
→ NameNode manages metadata
→ DataNodes store blocks
→ Files are divided into blocks
→ Blocks are distributed across the cluster
This design ensures that even if some machines fail, the data remains accessible.
Block Storage in Hadoop
Hadoop stores data in blocks instead of full files.
For example:
If you upload a 1GB file and the block size is 128MB, Hadoop will divide the file into:
1GB = 1024MB
1024 / 128 = 8 blocksThese blocks are then distributed across different DataNodes.
This approach provides two advantages:
1. Parallel Processing
Multiple blocks can be processed simultaneously on different machines.
2. Fault Tolerance
If one machine fails, another machine with the replicated block can serve the data.
Data Replication in Hadoop
One of the most powerful features of Hadoop is data replication.
By default, Hadoop stores 3 copies of each block across different DataNodes.
Example:
Block B1 → DataNode1, DataNode4, DataNode7
Block B2 → DataNode2, DataNode5, DataNode8
Block B3 → DataNode3, DataNode6, DataNode9 If one DataNode crashes, Hadoop can still retrieve the data from other replicas.
This makes Hadoop extremely reliable for large-scale data systems.
Hadoop Read and Write Operations
Let’s understand how Hadoop reads and writes data in the cluster.
How Hadoop Writes Data
When a client uploads a file to Hadoop, the following steps occur:
- The client contacts the NameNode
- NameNode checks permissions and metadata
- The file is divided into blocks
- NameNode identifies DataNodes for storing blocks
- Blocks are written to the DataNodes
- Replication copies are created automatically
The client communicates directly with DataNodes to write the blocks.
How Hadoop Reads Data
The read process works slightly differently.
Steps:
- Client requests file from NameNode
- NameNode returns block locations
- Client directly contacts the nearest DataNode
- Data blocks are streamed to the client
This design reduces the load on the NameNode and improves performance.

Hadoop Rack Awareness
In large data centers, machines are organized into racks.
Hadoop uses a feature called rack awareness to store block replicas across different racks.
Why?
Because if one rack fails (for example due to power failure or network issues), Hadoop can still retrieve the data from another rack.
This increases data reliability and availability.
HDFS Working Example
The following diagram shows how Hadoop clients interact with NameNode and DataNodes while reading or writing data.
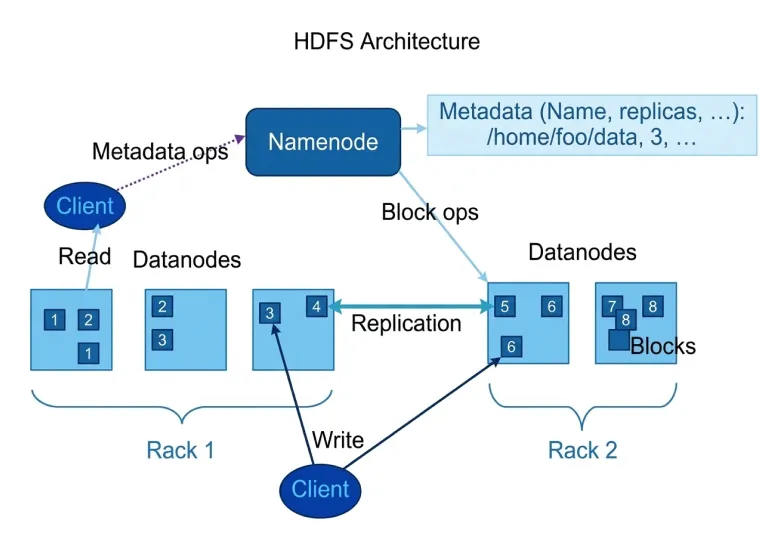
From the diagram we can observe:
→ Client communicates with NameNode for metadata
→ Data transfer happens directly between client and DataNodes
→ Replication occurs between DataNodes
→ Data blocks are distributed across racks
This architecture allows Hadoop to process petabytes of data efficiently.
Advantages of Hadoop Architecture
Hadoop became widely popular in big data systems because of several advantages.
1. Scalability
Hadoop clusters can easily scale from a few machines to thousands of nodes.
2. Fault Tolerance
Data replication ensures that system failures do not cause data loss.
3. Cost Efficiency
Hadoop runs on commodity hardware, which is much cheaper than traditional enterprise systems.
4. Parallel Processing
Multiple nodes process data simultaneously, improving speed and performance.
5. Flexibility
Hadoop can handle:
→ Structured data
→ Semi-structured data
→ Unstructured data
This makes it ideal for modern data-driven organizations.
Where Hadoop Is Used
Hadoop is widely used in industries that handle large datasets.
Common use cases include:
→ Data warehousing
→ Log processing
→ Recommendation systems
→ Fraud detection
→ Social media analytics
→ Machine learning pipelines
Companies like Amazon, Facebook, Yahoo, and LinkedIn have used Hadoop to process massive amounts of data.
If you want to test your understanding of Hadoop concepts, you can try this Hadoop Practice Test. It includes questions on Hadoop architecture, HDFS, and distributed data processing.
Learning Hadoop and Big Data Skills
Understanding systems like Hadoop architecture is an important step for developers who want to work in data engineering, backend systems, or distributed computing.
However, many developers struggle because distributed systems concepts can feel complex initially.
This is where structured learning becomes helpful.
Platforms like Bosscoder Academy help developers learn system design and distributed systems used in real-world applications. Understanding technologies like Hadoop helps developers see how large-scale data systems work in modern tech companies.
Conclusion
Hadoop architecture is designed to solve one of the biggest challenges in modern computing i.e., processing massive datasets efficiently.Instead of using a single powerful machine, Hadoop spreads data and processing across many machines, making the system scalable, reliable, and efficient.
The core idea behind Hadoop is simple: the NameNode manages metadata and the overall structure, while DataNodes store the actual data blocks. With features like block storage, data replication, and rack awareness, Hadoop can process extremely large datasets used in modern big data systems.
For developers interested in data engineering, backend systems, or distributed computing, understanding Hadoop architecture is a valuable skill. It helps you understand how large-scale data platforms are designed and how modern companies manage massive data workloads.
If you want to explore more about big data and data engineering concepts, check out these related resources:
- Understanding the Basics of Big Data
- Data Engineering Projects with Source Code
- Data Engineering Roadmap 2026
- How to Become a Big Data Analyst
These blogs can help you understand the skills, tools, and career paths in big data and data engineering.
Frequently Asked Questions (FAQs)
Q1. What is Hadoop architecture?
Hadoop architecture is the design of the Apache Hadoop ecosystem that allows data to be stored and processed across multiple machines in a distributed environment. It mainly consists of components like HDFS for storage, YARN for resource management, MapReduce for data processing, and Hadoop Common for utilities.
Q2. What are the main components of Hadoop architecture?
The main components of Hadoop architecture include:
→ HDFS (Hadoop Distributed File System): Stores large datasets across multiple machines
→ YARN (Yet Another Resource Negotiator): Manages cluster resources and job scheduling
→ MapReduce: Processes large datasets using parallel computing
→ Hadoop Common: Provides libraries and utilities used by other modules
These components work together to enable distributed storage and large-scale data processing.
Q3. What is the role of NameNode and DataNode in Hadoop?
In Hadoop, the NameNode and DataNodes are key components of Hadoop Distributed File System.
→ NameNode acts as the master node and manages metadata such as file locations and block information.
→ DataNodes are worker nodes that store the actual data blocks and handle read/write operations.
Together, they enable efficient distributed data storage.
Q4. Why is Hadoop used in big data systems?
Hadoop is widely used in big data systems because it provides:
→ Scalability: Can handle petabytes of data across thousands of machines
→ Fault tolerance: Data replication prevents data loss
→ Cost efficiency: Runs on low-cost hardware
→ Parallel processing: Multiple nodes process data simultaneously
Because of these advantages, companies use Hadoop to process and analyze massive datasets efficiently.







